모델은 어떻게 작동하는가?
먼저, 기계학습 모델이 어떻게 작동되고 어떻게 사용되는지 알아보는 것부터 시작하겠습니다. 이미 좀 배웠다면 좀 시시할테지만, 곧 파워풀한 모델을 만들것이니 일단 들어보죠.
당신의 친척이 부동산으로 수백만 달러를 벌었습니다. 그는 당신의 데이터 사이언스에 대한 관심을 보고 비즈니스 파트너가 되달라고 오퍼를 했습니다. 그는 돈을 제공할 것이고 당신은 다양한 주택들의 가치를 예측하는 모델을 제공할 것입니다.
당신은 그에게 과거의 그가 부동산의 가치를 어떻게 예상했는지를 물어봤고, 그는 그저 직감이라고 답했습니다. 하지만 더 많은 질문들을 통해 그가 과거에 주택 가격의 패턴을 알아냈고, 그 패턴을 그가 고려 중인 새로운 주택을 예측하는 데에 사용한 것을 알 수 있었습니다.
기계학습은 동일한 방식으로 작동합니다. 먼저, 의사결정트리라고 불리는 모델에서부터 시작하겠습니다. 더 정확한 예측을 제공하는 핫한 모델들이 있지만 의사결정트리는 이해하기 쉽고, 데이터 사이언스에서 몇몇 최고의 모델들의 기반이 되거든요.
간단하게, 가장 심플한 의사결정트리부터 시작하겠습니다.

이것은 주택들을 딱 두 가지 카테고리로 나눕니다. 고려 중인 모든 주택의 예측 가격은 같은 카테고리인 주택들의 역사적 평균 값입니다.
우리는 데이터를 사용해서 그 주택들을 어떻게 두 그룹으로 나눌지 결정하고 다시 각 그룹의 예측 가격을 결정합니다. 이렇게 데이터에서 패턴을 찾는 단계를 모델을 fitting 또는 training 한다고 합니다. 모델을 fit하기 위해 사용된 데이터를 training data라고 부릅니다.
얼마나 모델이 fit한가(즉, 데이터를 어떻게 분할하는가)에 대한 자세한 내용은 복잡하니까 나중을 위해 미뤄둡시다. 일단 모델이 fit(학습)되면, 추가적인 주택들의 가격을 예측하기 위해 새로운 데이터를 적용해볼 수 있습니다.
의사결정트리 개선하기
아래의 두 의사결정트리 중 실제 부동산 데이터로 학습된 결과에 가까워보이는 것은 어떤 것입니까?

아마도 왼쪽의 의사결정트리(Decision Tree 1)같습니다. 왜냐하면, 침실이 2개 이상인 주택이 2개 이하인 주택보다 높은 가격에 거래된다는 현실적인 패턴이 반영됐기 떄문입니다. 이 의사결정트리 모델의 가장 큰 단점은 화장실의 개수라던지 대지의 크기, 위치 등 집값에 영향을 주는 대부분의 요소들이 반영되지 않았다는 것입니다.
당신은 더 많은 "분할(splits)"을 갖는 트리를 사용해서 더 많은 요소를 모델에 반영할 수 있습니다. 이를 깊은(deeper) 트리라고 부릅니다. 각 주택의 대지의 총 크기까지 고려하는 의사결정 트리는 아래와 같은 모양일 것입니다.
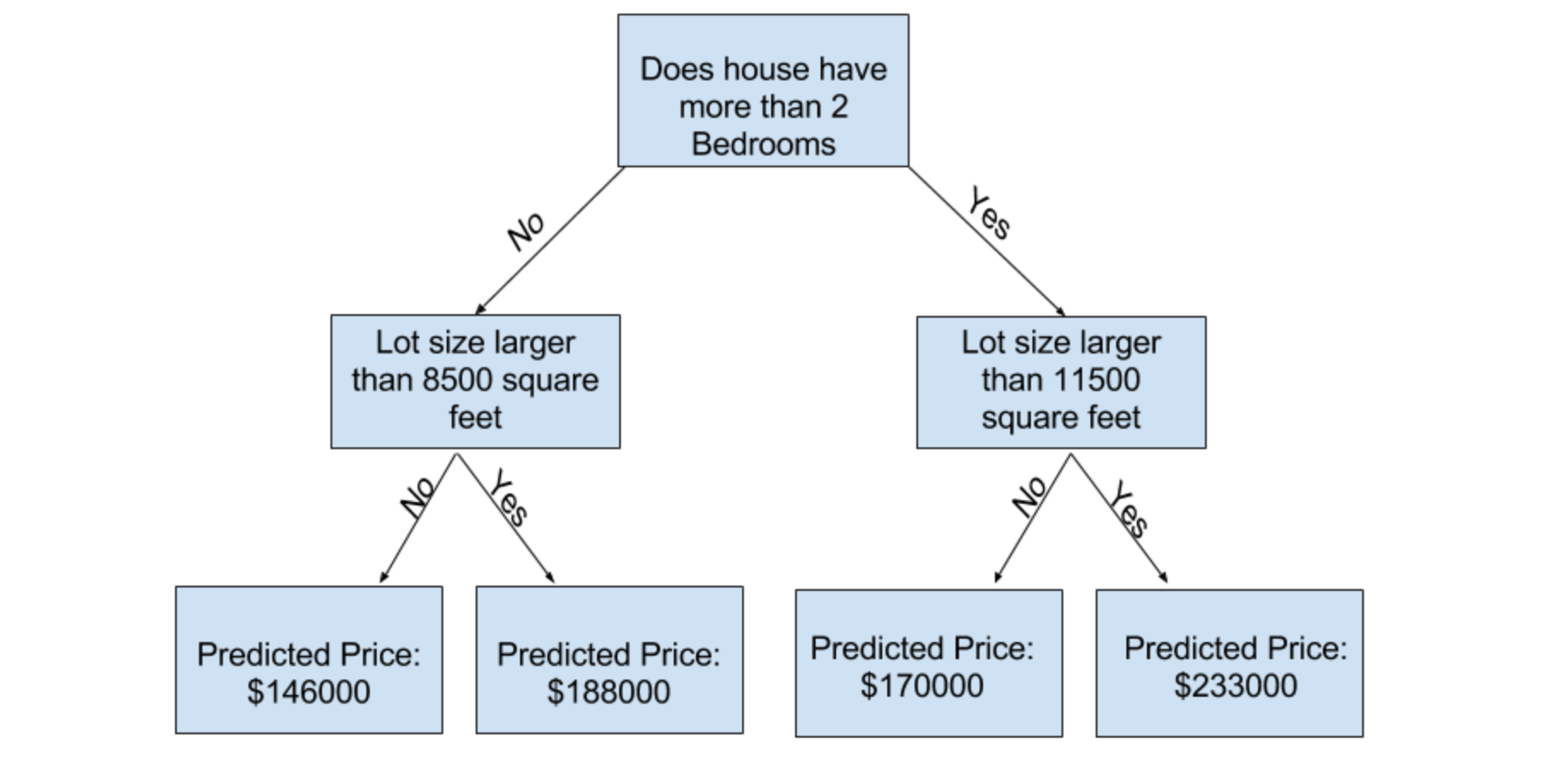
당신은 의사결정트리에서 주택의 특징과 일치하는 선택을 따라가면서 어떤 주택이든 그 가격을 예측해볼 수 있습니다. 주택의 예측 가격은 트리의 가장 아래에 있죠. 우리가 예측을 하는 이 가장 아래 지점을 잎사귀(leaf)라고 부릅니다.
나뭇잎들에 있는 "분할들(splits)"과 "값들(values)"은 데이터에 의해 결정됩니다. 자, 이제 당신이 작업할 데이터를 확인하세요!
캐글의 Courses 중 Intro to Machine Learning의 튜토리얼을 번역하며 공부해봤습니다.
혹시라도 잘못된 내용이 있다면, 말씀해주시면 감사하겠습니다!
'STUDY LOG > Kaggle' 카테고리의 다른 글
| Intro to Machine Learning(3) (0) | 2021.09.23 |
|---|---|
| 캐글(Kaggle) Notebook 실습(Exercise)하는 방법 (0) | 2021.09.22 |
| Intro to Machine Learning(2) (0) | 2021.09.22 |
| 캐글(Kaggle) 등급 알아보기 (0) | 2021.09.22 |
| 캐글(Kaggle) 시작하기 (0) | 2021.09.02 |