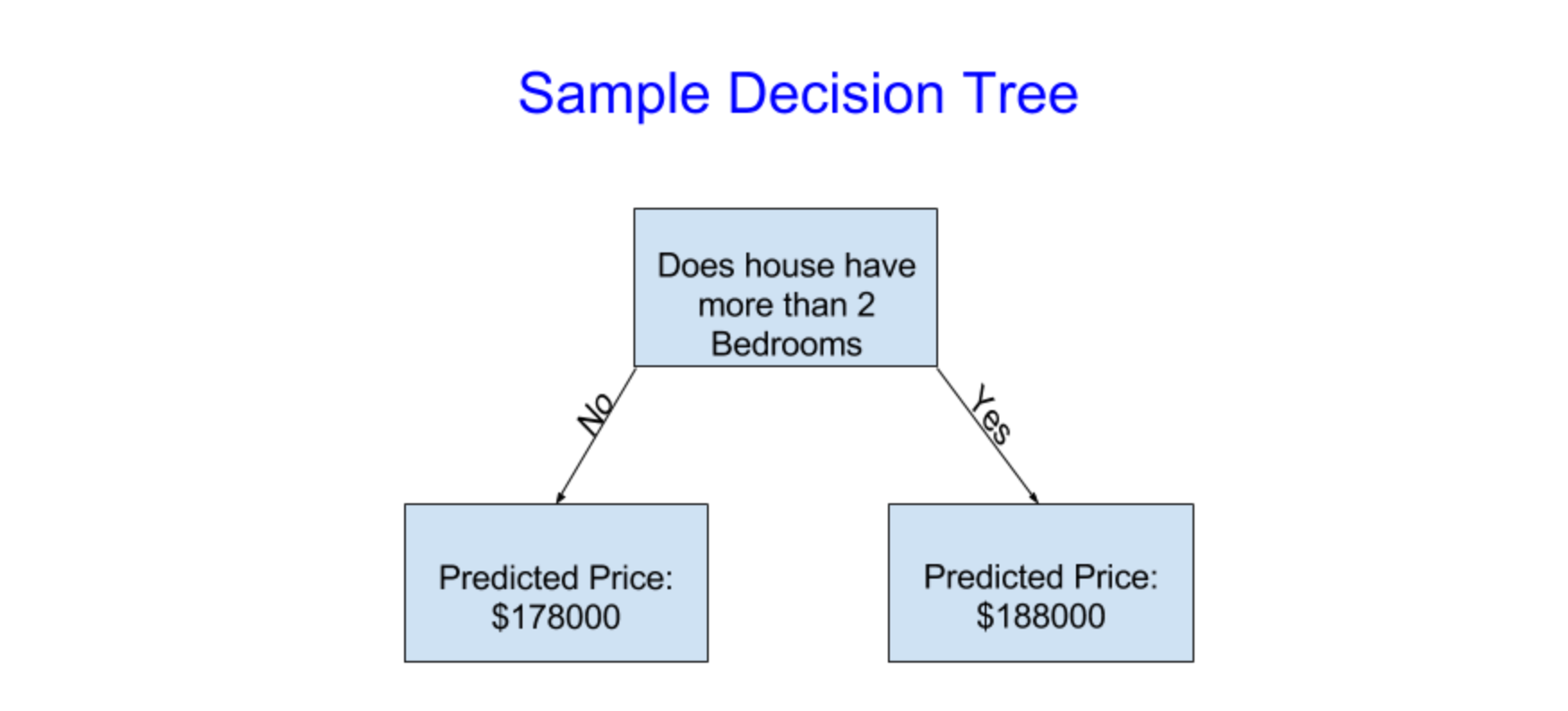
Machine Learning Competitions 당신의 성장을 확인하고 계속 발전하기 위해 기계 학습 시합의 세계에 들어오세요! 기계 학습 시합은 당신의 데이터 사이언스 기술과 당신의 진척도를 평가하기에 가장 좋은 방법입니다. 다음 실습으로 당신은 캐글 학습 유저들을 위한 주택 가격 시합에 예측치를 만들고 제출하는 것입니다. 이것으로 Intro to Machine Learning 코스를 마치겠습니다. 이렇게 Intro to Machine Learning의 모든 수업을 번역하며 공부해봤습니다. 결국 이 코스를 요약하자면, scikit-learn이라는 머신러닝 라이브러리를 활용해본다. decision tree와 random forest를 사용해본다. 만들어진 모델이 잘 동작하는지에 대한 기준을 MAE로..